
Estimation in software development has always been complex. We've tried function points, COCOMO models, story points, t-shirt sizes, and countless variations. Some teams have abandoned estimation entirely. Others have embraced AI tools that promise to do the estimating for us.
After working with teams across industries, one thing is clear: there's no universal best practice. But some approaches work reliably in specific contexts, and some approaches consistently fail. Here's what we've learned about estimation strategies that actually deliver value going into 2026.
The Problem with Estimation
Before diving into techniques, it's worth acknowledging why estimation is hard. Software development involves uncertainty at multiple levels: unclear requirements, unknown technical challenges, dependencies on external systems, and the inherent difficulty of predicting creative work.
Most estimation failures share a root cause: we treat estimates as commitments rather than forecasts.
- A forecast says, "Based on what we know, here's our best prediction."
- A commitment says, "This is what we will deliver."
Conflating the two creates pressure to underestimate risks and overestimate certainty.
Effective estimation acknowledges uncertainty explicitly. A single number like "5 weeks" is almost always wrong. "3-8 weeks depending on API complexity" is more honest and more useful.

Time-Tested Techniques That Still Work
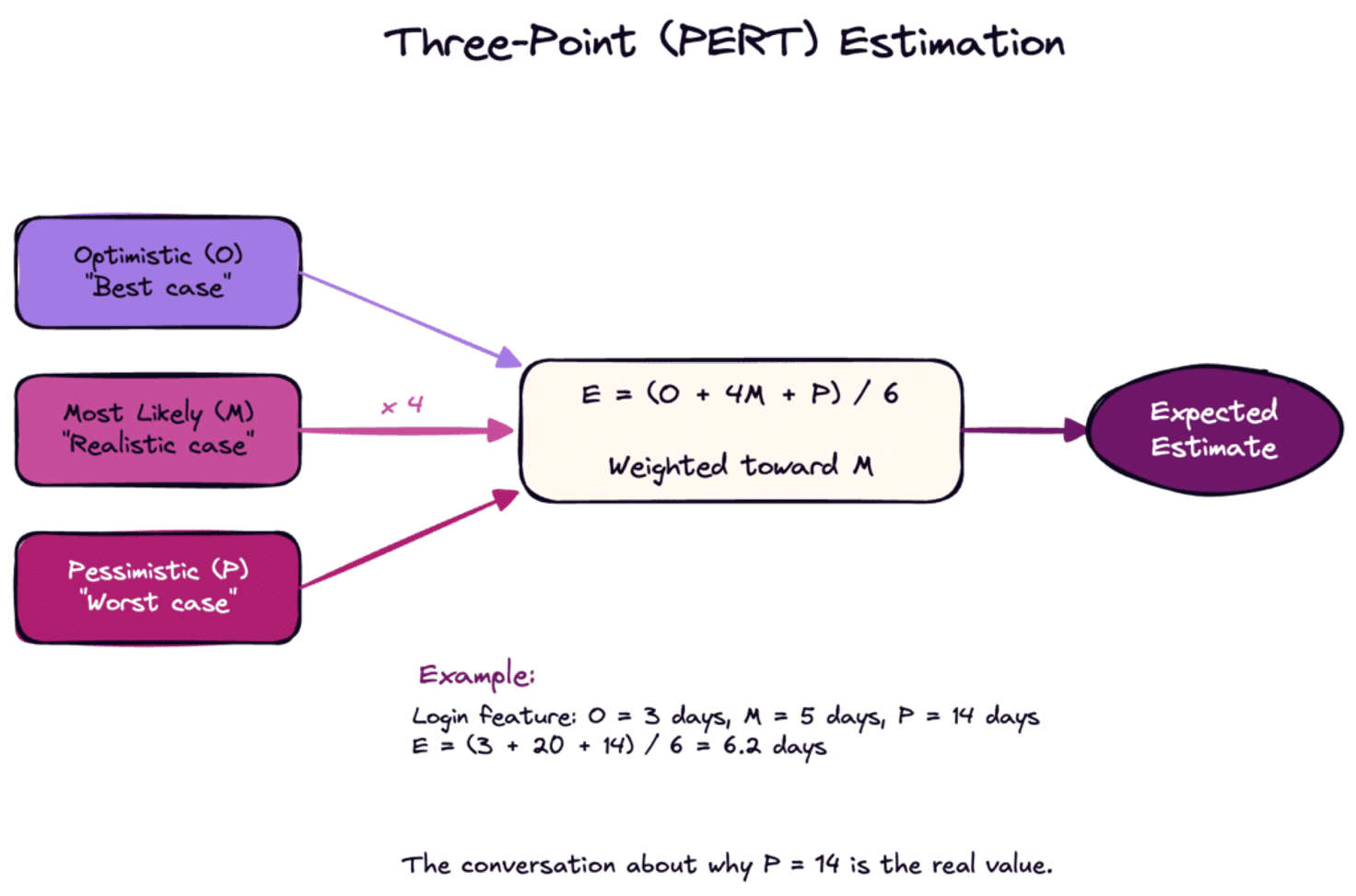
Three-Point Estimation
Instead of a single estimate, provide three: optimistic (best case), pessimistic (worst case), and most likely. This forces explicit consideration of uncertainty and gives stakeholders a realistic range.
The classic PERT formula weights these estimates:
Expected = (Optimistic + 4 × Most Likely + Pessimistic) / 6But the real value isn't the math. It's the conversation that produces three distinct estimates. When someone's optimistic estimate equals their pessimistic estimate, you know they haven't thought through the uncertainty.
Complexity + Uncertainty Decomposition
One of my favorite strategies comes from Jacob Kaplan-Moss, a technique that separates complexity from uncertainty. First, bucket tasks by complexity using consistent categories:
- Small: 1 day
- Medium: 3 days
- Large: 5 days
- Extra-Large: 10 days (should usually be broken down)
Then apply an uncertainty multiplier based on how well you understand the task:
- Low uncertainty (1.1x): You've done this exact thing before
- Moderate uncertainty (1.5x): Similar to past work with some unknowns
- High uncertainty (2.0x): New territory but familiar technology
- Extreme uncertainty (5.0x): Significant unknowns, may need spikes first
A medium task (3 days) with high uncertainty becomes 6 days. This approach makes assumptions explicit and highlights where risk reduction (research, spikes, prototypes) could narrow the range.
T-Shirt Sizing for Early Stages
For roadmap planning and early-stage feature discussions, t-shirt sizes (XS, S, M, L, XL) work well. They communicate relative effort without false precision.
The key is calibration. What does "Large" mean for your team? Document examples:
- Small: Add a new field to an existing form
- Medium: Build a new API endpoint with standard CRUD operations
- Large: Integrate with a third-party payment provider
- XL: Build a new user-facing feature with multiple screens
When teams share calibration examples, t-shirt sizing becomes surprisingly consistent.
Throughput-Based Approaches
Instead of predicting how long individual tasks will take, throughput-based estimation focuses on how many items a team completes per time period. This approach, popularized by Kanban practitioners, sidesteps the difficulty of individual task estimation.
The premise: if your team consistently completes 8-12 user stories per sprint, and your backlog has 50 stories, you can forecast approximately 4-6 sprints to completion. No need to estimate each story.
Prerequisites for throughput-based estimation:
- Consistent story sizing: Stories should be roughly similar in scope. If one story is 10x larger than another, throughput metrics become meaningless.
- Historical data: You need several sprints of completed work to establish a reliable throughput range.
- Stable team: Throughput changes when team composition changes.
The appeal is simplicity: stop debating whether a story is 3 or 5 points and just count how many you complete. The limitation is that it works best for mature teams with established patterns.
The #NoEstimates Perspective
The #NoEstimates movement, started by Woody Zuill and others around 2012, argues that estimation is often waste. If you can break work into small, similarly-sized pieces and maintain a steady flow, traditional estimation becomes unnecessary.
The strongest argument for #NoEstimates: estimation doesn't improve delivery. A project estimated at 6 months doesn't finish faster than one with no estimate. And the time spent estimating could be spent building.
The strongest argument against: business decisions require forecasts. Choosing between projects, staffing decisions, and customer commitments all need some prediction of effort. Saying "just start and see" doesn't work when you have 15 potential projects and resources for 3.
The practical takeaway: #NoEstimates works in specific contexts. Teams with consistent velocity, similarly-sized work items, and stakeholders comfortable with flow-based delivery can often skip traditional estimation. But most organizations need some forecasting capability, even if it's rough.
AI-Assisted Estimation: Where We Are in 2026
A relatively new option is AI estimation tools, and lately, they have improved significantly. Platforms like CostGPT, Quanter, and built-in features in tools like ClickUp analyze historical data and natural language requirements to suggest estimates.
What AI does well:
- Pattern matching: Identifying similar past work and using those actuals as a baseline
- Consistency: Applying the same logic across all estimates, reducing individual bias
- Speed: Generating initial estimates for large backlogs quickly
What AI still struggles with:
- Novel work: Tasks unlike anything in the training data
- Context: Understanding team-specific constraints, technical debt, or organizational factors
- Requirements ambiguity: AI can't resolve unclear requirements; it just estimates the ambiguity
The most effective use of AI estimation is as a starting point, not a final answer. Generate AI estimates, then have the team review and adjust based on context the AI can't see. This combines AI's consistency with human judgment.
Choosing the Right Approach

Different situations call for different estimation strategies:
For roadmap planning (quarters out): T-shirt sizing with calibrated examples. Precision is impossible at this horizon anyway.
For sprint planning (weeks out): Three-point estimation or complexity + uncertainty decomposition. You have enough information to be more precise.
For client proposals: Range-based estimates with explicit assumptions. "This feature will take 2-4 weeks, assuming the API documentation is accurate and we have access to a sandbox environment."
For mature teams with steady flow: Throughput-based forecasting. Let historical velocity drive predictions.
For large backlogs needing quick triage: AI-assisted initial estimates, refined by team review.
Making Estimates Useful
The technique matters less than how estimates are used. Principles that make any approach more effective:
Always estimate in ranges. Single-point estimates create false confidence. "3-5 days" is more honest than "4 days."
State assumptions explicitly. Every estimate depends on assumptions. Write them down. "Assumes we can reuse the existing authentication system" clarifies scope and highlights risks.
Track actuals and retrospect. Compare estimates to actual effort. Not to punish misses, but to calibrate future estimates. If you consistently underestimate integration work, adjust your multipliers.
Reduce uncertainty through discovery. High-uncertainty estimates should trigger spikes or research before commitment. A 2-day investigation that narrows a 2-10 week estimate to 3-5 weeks is time well spent.
Separate estimation from commitment. An estimate is a forecast. A commitment is a promise. Keep them distinct in conversations with stakeholders.
The Story Points Debate
Story points remain popular. According to the 17th Annual State of Agile Report, Scrum remains the most popular team-level methodology at 63% adoption, and velocity, its story-point-based metric, is one of the most widely tracked agile metrics.
But story points have problems:
- They're often converted to hours anyway, defeating the purpose
- Different teams have different scales, making cross-team comparison meaningless
- Planning poker sessions can consume significant time
- Velocity metrics are easily gamed
If your team uses story points effectively and stakeholders understand they're relative measures, keep using them. If story points have become a source of dysfunction, consider alternatives like throughput-based approaches or simple t-shirt sizing.
The Bottom Line
Estimation is a means to an end. The goal is making good decisions about what to build and when. Any technique that helps you make better decisions is working. Any technique that creates false certainty or wastes time without improving decisions is not.
The best teams we've worked with share a few traits: they acknowledge uncertainty explicitly, they track and learn from their estimates, and they match their estimation approach to the decision being made. Roadmap discussions don't need sprint-level precision. Client proposals need different rigor than internal planning.
Pick an approach that fits your context, use it consistently, and refine based on results. That's the estimation strategy that actually works.
Accurate estimation is how we keep client projects on time and on budget. We've refined these practices over a decade of building custom software and web applications. If you need a development partner who takes the guesswork out of planning, let's talk.

