
Data Privacy is the New Standard
When a new user signs up for your product or service, you have certain legal and ethical responsibilities to that individual. One of those responsibilities is making sure that any information they share with you is kept private and secure. Over the past decade, we’ve seen what can happen when companies are neglectful with personal data, and in 2018, strong privacy practices can ensure that your company is making headlines for the right reasons.
GDPR and Data Privacy
Under the European Union's General Data Protection Regulation (GDPR), companies have a new legal incentive to protect and keep private any data they’ve collected on users. The deadline for implementation was May 25th, 2018, but it’s never too late to start taking steps towards compliance. This post relies on a basic understanding of GDPR, so if you’re completely unfamiliar with the new rules, read through our introduction to GDPR compliance.
Pseudonymization and Anonymization: Pieces of the Puzzle
Pseudonymization is the obfuscation of personal data so that it can’t be read in plain text without additional information. Anonymization is the permanent de-identification of user data, rendering a set of data completely anonymous. Both of these methods make a data set unreadable to potential threats, ensuring the privacy of personal data.
What Are the Benefits?
Security
As stated, data obfuscation practices allow you to store or process data in a format that is unusable as-is to bad actors. These techniques limit the exposure of personal data to both internal employees who are given access and external adversaries who gain access to your networks maliciously.
Compliance
While there are any number of steps an organization can take to ensure that it is compliant with the regulations, GDPR recommends pseudonymization and anonymization as ways of bolstering user privacy. In the event of a breach, the supervisory authority in charge of enforcing GDPR may take into consideration whether or not you took the necessary steps to secure personal data before deciding on the severity of punishment. We suggest consulting with a legal professional when plotting your plan for compliance, but pseudonymization and anonymization are definitely things to consider.
User Trust
Now more than ever, users who sign up for your product expect that their personal data will be handled with care. By implementing the techniques outlined in this article, your organization can be one step closer to ensuring that your users' personal data is never exposed. Keep reading to find out more about pseudonymization and anonymization, the differences between them, and some popular ways of implementing them.
Data Pseudonymization
Pseudonymization is an approach recommended by GDPR for treating personal data so that it cannot be used to identify individual users without the use of additional information. Although there are a variety of pseudonymization techniques, they all involve replacing data with a placeholder value, or a pseudonym. This pseudonym may be a masked version of a record or a token used for retrieving the original value. The goal of pseudonymization is to limit the exposure of personal data to internal and external threats by creating a data set which is both obfuscated and realistic.
A few examples of pseudonymization techniques include:
Data Masking
Data masking is a pseudonymization technique that involves altering or replacing a record or part of a record without changing its format. For example, a user's unmasked social security number (SSN) might be stored as 679-69-8549, but a masked SSN using a technique to substitute the digits might look like 145-126-7741.
To mask data, characters in a record may be shuffled or substituted, and words may be substituted or obscured completely. The result is a realistic data set that cannot be reverse engineered or re-identified without additional information.
Data masking limits the exposure of personal data while still allowing for some level of operational efficacy.
Approximation
Approximation is a technique for replacing specific personal data with less specific values. For example, if a user's date of birth is August 20, 1997, then an approximated record might be stored as July 1 - September 25, 1997, or even just 1997. This allows an organization to remove as much specific personal data as possible from a data set while still being able to derive useful information from it.
Encryption
Encryption is a cryptographic process that converts data into an unreadable format (ciphertext) so that only individuals or systems with access to the appropriate key can decrypt and read it. While not explicitly mandatory, encryption is mentioned throughout GDPR, and should be used when appropriate to protect user data.
Data can be encrypted while in storage (at rest), and can also be encrypted when being shared or transferred (in transit). Note that there’s no one set of rules for when or how to encrypt personal data, and that encryption can place a heavy load on an application’s compute resources. It’s up to your organization to decide when to encrypt, but we strongly encourage you to look for opportunities to do so.
Tokenization
To tokenize a piece of data is to replace it with a unique token that acts as a stand-in which can be used to retrieve the original value. Tokenization is often used in payment processing solutions such as Apple Pay or PayPal.
For example, a user's credit card number is represented by a token. When making a purchase, the merchant receiving payment only has access to the token, rather than the actual credit card number. Since Apple Pay knows the relationship between the token and credit card number, it can take the transaction information, retrieve the credit card number based on the token, and process it like a normal purchase.
Protecting your organization is really about protecting your users. Cuttlesoft can help secure private data, and reduce the damage done by leaks.
Data Anonymization
Anonymization is the permanent de-identification of a data set so that no party will be able to identify the individuals in reference no matter what additional data they possess. The main difference between pseudonymization and anonymization is that anonymization is an irreversible process. Since anonymized data cannot be used to identify any individual, it is no longer considered personal data and as such does not fall under the purview of GDPR.
True anonymization is difficult to achieve. Anonymization is most useful in research, publishing data, and other use cases where identifying individual users isn’t necessary. Your organization should weigh the costs and benefits (both legal and technical) of anonymization before deciding to implement this data privacy technique.
A few examples of anonymization techniques include:
Noise Addition
Noise addition is the process of making random, statistically insignificant changes to a data set that preserves its processability while de-identifying personal data. Noise addition corrupts a data set by an unknowable amount, rendering it anonymous.
For example, a database containing users' ages could be anonymized by randomly adding or subtracting a number between 1 and 10 to the age records, and then deleting the attached name records. This would allow you to know the average age of your users (within a margin of error), but would prevent an adversary from learning their real dates of birth. This process should preferably be automated and truly random to prevent reverse engineering.
Aggregation

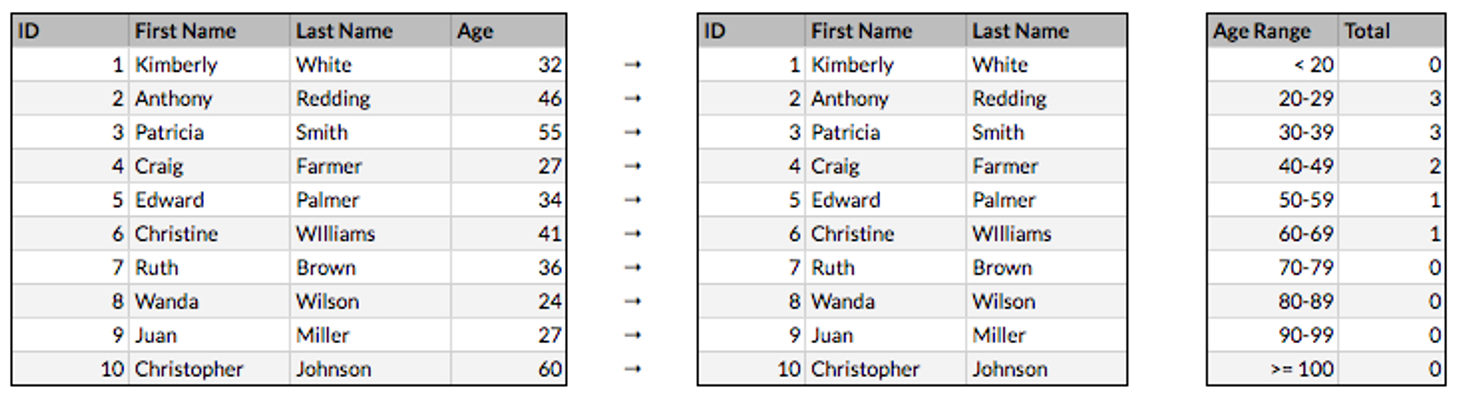
To create an aggregate data set, rather than collecting data about individuals, you’d decide which data is relevant, record only that information, and store it in a summarized form. This could be the number of individuals who fit a certain description, the number of events that occur within a given time period, or some other data points which you decide to correlate.
For example, if you wanted information on your users' heights, you could make a tally for every person between four and five feet, every person between five and six feet, and so forth. As long as you didn’t collect their information in the process, the data set would be an anonymous summary of user heights.
If you wanted to aggregate an existing data set, the same technique could be applied. If there was a data set with users’ names and heights, you’d tally the height counts as before, and record the tallies in a new dataset. Then, you’d permanently delete the height data from the individual user records. The result would be an anonymized summary of users’ heights that would be impossible to tie back to the individual users.
Conclusion
The purpose of this post is to outline personal data privacy techniques as they relate to data security, user privacy, and regulations like GDPR. That being said, each organization, application, and data set is unique, and your organization will need to decide what forms of privacy are most appropriate given your particular circumstances. If your organization is truly committed to user privacy, pseudonymization and anonymization are small but integral pieces of a larger security and compliance framework.
When it comes to privacy and security, protecting yourself is really about protecting your users. They've trusted you with their information, so it's up to you to do everything you can to keep it safe. As security and compliance evolve, staying up-to-date on the latest threats and mitigation techniques is essential.
If you need advice on making your software compliant with GDPR, contact one of Cuttlesoft's software experts today.

